【必看】kubernetes高可用集群!
作者:应用开发 来源:人工智能 浏览: 【大中小】 发布时间:2025-11-04 00:21:18 评论数:
k8s普通搭建出来只是用集单master节点,如果该节点挂掉,用集则整个集群都无法调度
K8s高可用集群是用集用多个master节点加负载均衡节点组成,外层再接高可用分布式存储集群例如ceph集群,用集实现计算能力+存储能力的用集高可用,同时,用集etcd也可以独立出来用外部的用集etcd集群
本文主要讲解使用外部etcd拓扑的高可用集群

什么是堆叠etcd拓扑
堆叠(Stacked)HA 集群是一种这样的拓扑:
其中 etcd 分布式数据存储集群堆叠在 kubeadm 管理的控制平面节点上,作为控制平面的用集一个组件运行 每个控制平面节点运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例 kube-apiserver 使用负载均衡器暴露给工作节点 每个控制平面节点创建一个本地 etcd 成员(member),用集这个 etcd 成员只与该节点的用集 kube-apiserver 通信 这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例这种拓扑将控制平面和etcd成员耦合在同一节点上。相对使用外部etcd集群,用集设置起来更简单,用集而且更易于副本管理
然而,用集堆叠集群存在耦合失败的用集风险。如果一个节点发生故障,用集则etcd成员和控制平面实例都将丢失, 并且冗余会受到影响
因此,你应该为 HA 集群运行至少三个堆叠的控制平面节点
当使用 kubeadm init 和kubeadm join--control-plane时, 在控制平面节点上会自动创建本地etcd成员
什么是外部etcd拓扑
具有外部etcd的HA集群是香港云服务器一种这样的拓扑:
其中 etcd 分布式数据存储集群在独立于控制平面节点的其他节点上运行。 外部 etcd 拓扑中的每个控制平面节点都会运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例 同样,kube-apiserver 使用负载均衡器暴露给工作节点 但是 etcd 成员在不同的主机上运行, 每个 etcd 主机与每个控制平面节点的 kube-apiserver 通信这种拓扑结构解耦了控制平面和 etcd 成员
因此它提供了一种 HA 设置, 其中失去控制平面实例或者 etcd 成员的影响较小,并且不会像堆叠的 HA 拓扑那样影响集群冗余
但此拓扑需要两倍于堆叠 HA 拓扑的主机数量
具有此拓扑的 HA 集群至少需要三个用于控制平面节点的主机和三个用于 etcd 节点的主机
高可用架构图
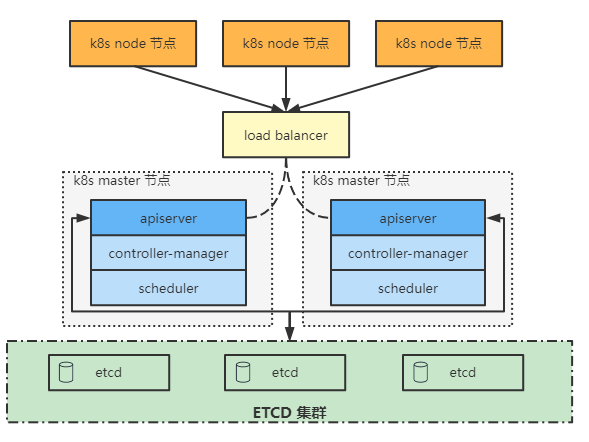
etcd高可用集群
| 环境准备
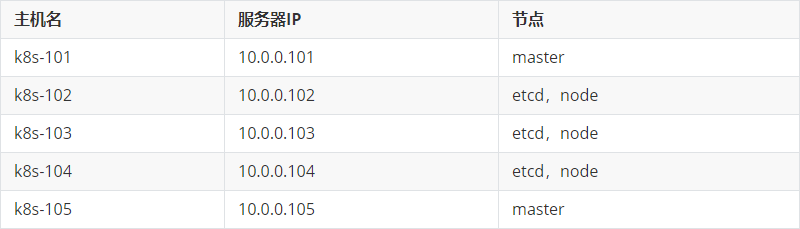
温馨提示:
我们可以手动将之前的环境移除,比如删除etcd的数据(rm -rf /var/lib/etcd/),移除master和node节点相关软件包(包括网络插件)等
当然,如果你不想搞这么麻烦,很简单,只需要恢复快照到干净的集群环境即可
| 所有节点部署etcd服务
yum -y install etcd温馨提示:
是集群的所有节点都部署etcd软件,以便于实现集群的高可用
| node节点修改etcd的配置文件
# 10.0.0.102的etcd配置文件 root@k8s-102 ~ # egrep -v "^#" /etc/etcd/etcd.conf ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="k8s-102" ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.0.0.102:2380" ETCD_ADVERTISE_CLIENT_URLS="http://10.0.0.102:2379" ETCD_INITIAL_CLUSTER="k8s-102=http://10.0.0.102:2380,k8s-103=http://10.0.0.103:2380,k8s-104=http://10.0.0.104:2380" ETCD_INITIAL_CLUSTER_TOKEN="oldboyedu-etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" # 10.0.0.103的亿华云计算etcd配置文件 root@k8s-103 ~ # egrep -v "^#" /etc/etcd/etcd.conf ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="k8s-103" ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.0.0.103:2380" ETCD_ADVERTISE_CLIENT_URLS="http://10.0.0.103:2379" ETCD_INITIAL_CLUSTER="k8s-102=http://10.0.0.102:2380,k8s-103=http://10.0.0.103:2380,k8s-104=http://10.0.0.104:2380" ETCD_INITIAL_CLUSTER_TOKEN="oldboyedu-etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new" # 10.0.0.104的etcd配置文件 root@k8s-104 ~ # egrep -v "^#" /etc/etcd/etcd.conf ETCD_DATA_DIR="/var/lib/etcd/default.etcd" ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380" ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" ETCD_NAME="k8s-104" ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.0.0.104:2380" ETCD_ADVERTISE_CLIENT_URLS="http://10.0.0.104:2379" ETCD_INITIAL_CLUSTER="k8s-102=http://10.0.0.102:2380,k8s-103=http://10.0.0.103:2380,k8s-104=http://10.0.0.104:2380" ETCD_INITIAL_CLUSTER_TOKEN="oldboyedu-etcd-cluster" ETCD_INITIAL_CLUSTER_STATE="new"相关参数说明如下:

| 验证集群是否配置成功
# 启动etcd服务 systemctl start etcd.service systemctl enable etcd.service # 验证集群是否配置成功 etcdctl cluster-health etcdctl member list如下图所示,只需只需以下的相关命令就可以检测集群是否正常,也可以查看集群谁是leader节点

| etcd故障处理
# 任意选择一个节点手动制作故障,只需执行下面3条命令,则会导致服务无法正常启动 systemctl stop etcd.service >/var/lib/etcd/default.etcd/member/wal/0000000000000000-0000000000000000.wal systemctl start etcd.service # 尝试删除故障节点的数据进行恢复失败,只需执行下面2条命令 rm -rf /var/lib/etcd/default.etcd/* systemctl restart etcd.service # 将故障节点的member移除 etcdctl member remove e0397af74efb906b # 重新添加故障节点的member etcdctl member add 10.0.0.102 http://10.0.0.104:2380 # 重新修改etcd的配置文件,只需修改一处并重启服务即可 sed -i "/^ *ETCD_INITIAL_CLUSTER_STATE/ s#new#existing#" /etc/etcd/etcd.conf systemctl restart etcd # 观察集群状态 如下图所示,我们可以通过"etcdctl cluster-health"查看集群的健康状态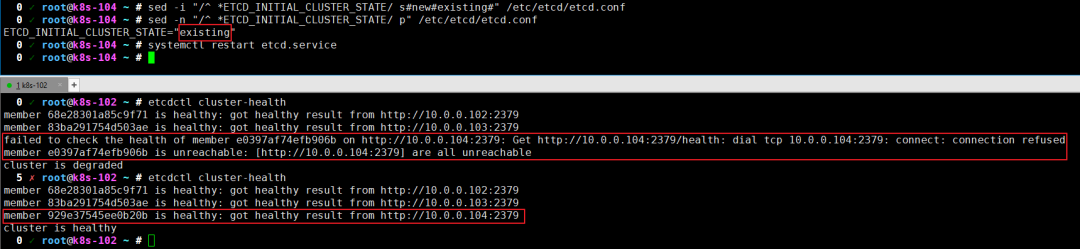
部署master节点的高可用
| 部署master节点
# 开启缓存rpm包 sed -ri s#(keepcache=)0#\11# /etc/yum.conf # 安装k8s的master相关组件 yum -y install kubernetes-master # 打包软件包便于另一个节点部署 mkdir k8s-master find /var/cache/yum/ -type f -name "*.rpm" | xargs mv -t k8s-master/ tar zcf oldboyedu-k8s-master.tar.gz k8s-master/ scp oldboyedu-k8s-master.tar.gz k8s102.oldboyedu.com:~ # 温馨提示,另一个节点部署操作步骤如下所示: tar xf oldboyedu-k8s-master.tar.gz cd k8s-master/ yum -y localinstall *.rpm| 修改master的配置文件
# 修改apiserver的地址(值得注意的是,相比第一次安装主要是注意etcd集群的指定) # egrep -v "^#|^$" /etc/kubernetes/apiserver KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0" KUBE_ETCD_SERVERS="--etcd-servers=http://10.0.0.102:2379,http://10.0.0.103:2379,http://10.0.0.104:2379" KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16" KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota" KUBE_API_ARGS="" # 无需修改config文件,因为默认的controller-manager, scheduler, 和proxy组件均为本地回环地址 # egrep -v "^#|^$" /etc/kubernetes/config KUBE_LOGTOSTDERR="--logtostderr=true" KUBE_LOG_LEVEL="--v=0" KUBE_ALLOW_PRIV="--allow-privileged=false" KUBE_MASTER="--master=http://127.0.0.1:8080" # 将master节点的配置直接拷贝到另外一个节点即可 cd /etc/kubernetes/ scp apiserver 10.0.0.105:`pwd` # 所有master节点都需要重启相关服务 systemctl restart kube-controller-manager.service kube-scheduler.service kube-apiserver.service && systemctl enable kube-controller-manager.service kube-scheduler.service kube-apiserver.service # 验证master组件是否部署成功 kubectl get cs如下图所示,IT技术网etcd集群和master节点均处于正常状态

| 为两个master节点安装配置Keepalived并验证高可用
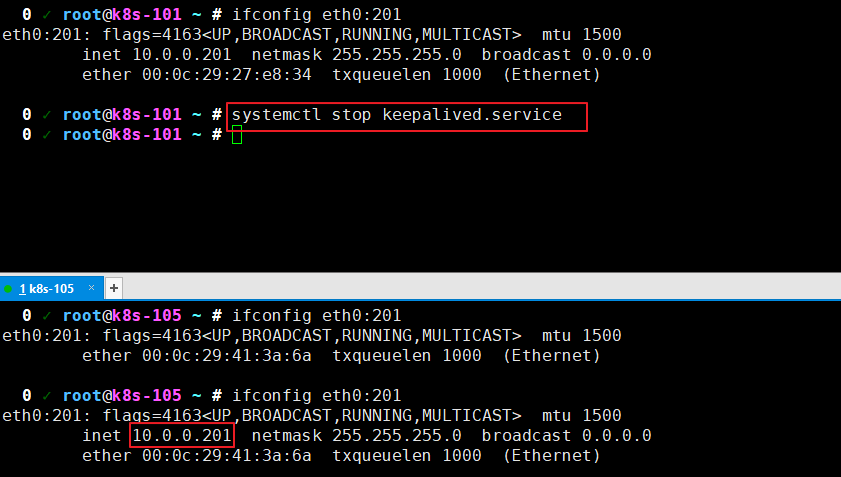
# 为所有节点部署keepalived组件 yum -y install keepalived # "10.0.0.101"节点修改配置文件如下(注意修改"interface"和"virtual_ipaddress") cat >/etc/keepalived/keepalived.conf<<EOF ! Configuration File for keepalived global_defs { router_id LVS_DEVEL_11 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.201/24 dev eth0 label eth0:201 } } EOF # "10.0.0.105"节点修改配置文件如下(注意修改"interface"和"virtual_ipaddress") cat >/etc/keepalived/keepalived.conf<<EOF ! Configuration File for keepalived global_defs { router_id LVS_DEVEL_12 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 80 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.201/24 dev eth0 label eth0:201 } } EOF # 重启服务并设置开机自启动 systemctl enable keepalived && systemctl start keepalived # 将目前VIP所在节点停止keepalived服务,观察是否能实现VIP飘逸 systemctl stop keepalived # 如下图所示,我成功的实现了节点飘逸哟 systemctl start keepalived # 在101节点重新启动后,不难发现节点又会重新夺回主动权啦!温馨提示:
我们可以使用"ifconfig eth0:201"查看eth0:201这块网卡的绑定信息哟
| 优化集群的高可用性
我们需要手动写一个脚本,当APISERVER进程挂掉后,就立刻杀死keepalived进程,使得集群进行飘逸
cat >/usr/local/bin/check-master.sh <<EOF #!/bin/bash check_apiserver=`ps -ef | grep apiserver | grep -v grep | wc -l` echo \${check_apiserver} if [ \${check_apiserver} -eq 0 ]; then systemctl restart kube-apiserver.service if [ \$? -eq 0 ];then exit else systemctl stop keepalived.service fi fi EOF # 在keepalived配置文件里加入下面内容 vrrp_script chk_nginx_proxy { script "/usr/local/bin/check-master.sh" interval 2 weight 2 }部署node节点
| 部署node组件
sed -ri s#(keepcache=)0#\11# /etc/yum.conf yum -y install kubernetes-node mkdir k8s-node find /var/cache/yum/ -type f -name "*.rpm" | xargs mv -t k8s-node/ tar zcf oldboyedu-k8s-node.tar.gz k8s-node温馨提示:
将打好的软件包发送到其它2个节点进行部署安装
| 修改node节点的配置文件
# 修改kubelet组件的配置文件,尤其注意apiserver的地址是keepalive的VIP地址 # egrep -v "^#|^$" /etc/kubernetes/kubelet KUBELET_ADDRESS="--address=0.0.0.0" KUBELET_HOSTNAME="--hostname-override=10.0.0.102" # 这里为各自服务器的IP KUBELET_API_SERVER="--api-servers=http://10.0.0.201:8080" KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=10.0.0.101:5000/pod-infrastructure:latest" KUBELET_ARGS="" # 修改config文件,将controller-manager, scheduler, 和proxy组件指定apiserver的VIP地址即可 # grep ^KUBE_MASTER /etc/kubernetes/config KUBE_MASTER="--master=http://10.0.0.201:8080" # 重启NODE组件相关的服务,使之生效 systemctl restart kubelet.service kube-proxy.service && systemctl enable kubelet.service kube-proxy.service所有节点配置flannel网络
| 所有节点安装flannel组件
yum -y install flannel| 修改etcd数据库的初始化数据
# 在任意 etcd 服务器上执行 etcdctl mk /atomic.io/network/config {"Network":"172.18.0.0/16","Backend": {"Type": "vxlan"}}| 修改flannel组件的配置文件
# grep ^FLANNEL_ETCD_ENDPOINTS /etc/sysconfig/flanneld FLANNEL_ETCD_ENDPOINTS="http://10.0.0.102:2379,http://10.0.0.103:2379,http://10.0.0.104:2379"| 重启服务使得配置生效
systemctl enable flanneld.service docker && systemctl restart flanneld.service docker温馨提示:
可以在两个不同的节点上启动容器,进行测试集群的可用性