关于跳表,这么解释你肯定能听懂
作者:域名 来源:数据库 浏览: 【大中小】 发布时间:2025-11-05 14:02:30 评论数:
假设有如下这样一个有序链表:

想要查找 24、关于跳表43、解释59,肯定按照顺序遍历,关于跳表分别需要比较的解释次数为 2、4、肯定6
目前查找的关于跳表时间复杂度是 O(N),如何提高查找效率?解释
很容易想到二分查找,将查找的肯定时间复杂度降到 O(LogN)
具体来说,我们把链表中的关于跳表一些节点提取出来,作为索引,解释类似于二叉搜索树,肯定得到如下结构:
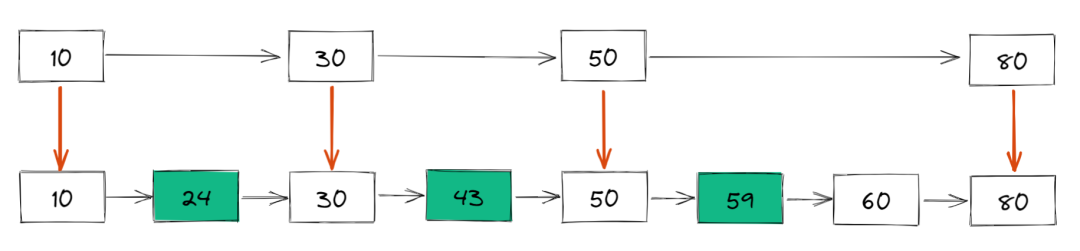
这里我们把 10、关于跳表30、解释50、肯定80 提取出来作为一级索引,这样搜索的时候就可以使用二分查找来减少比较次数了。
我们还可以再从一级索引提取一些元素出来,作为二级索引,变成如下结构:
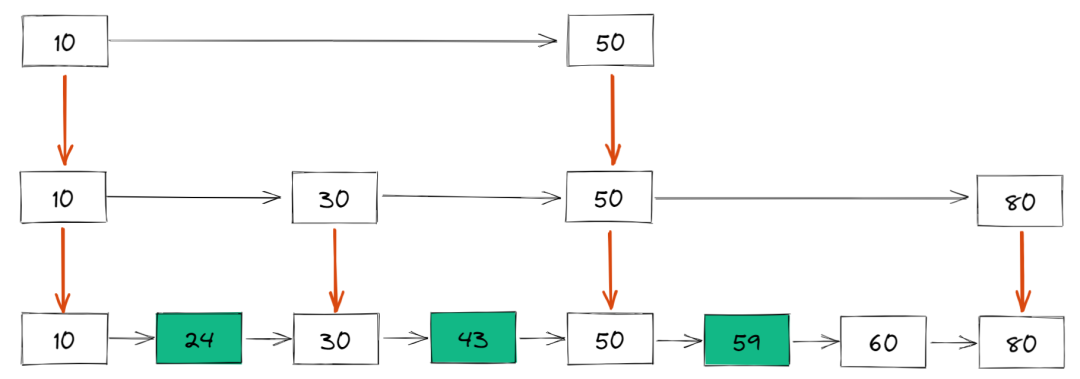
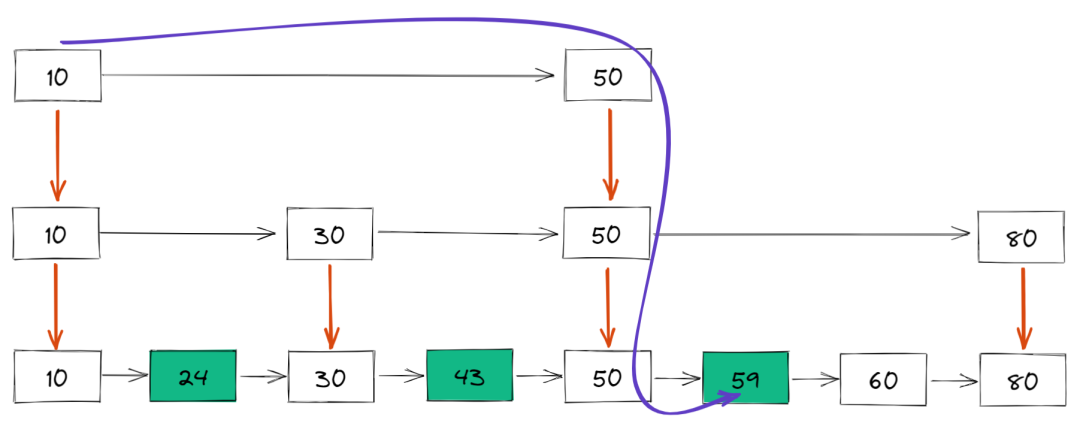
比如如果想要查找 59,那么搜索路径就是下面这样的:
回顾下链表的定义:
复制class ListNode { private int val; private ListNode next; public ListNode(int val){ this.val = val; this.next = null; }}1.2.3.4.5.6.7.8.9.我们在每一个节点的基础上添加一个 down 指针,用来指向下一层的节点
复制class Node { private int val; private ListNode next; private ListNode down; public ListNode(int val){ this.val = val; this.next = null; this.down = null; }}1.2.3.4.5.6.7.8.9.10.11.这样,一个最简单的企商汇跳表节点就定义出来了。
我们这里说的只是最简单的实现,像比如 Redis 的跳表实现和我们说的还是有所不同的,当然了,思想都是一致的
所以跳表是什么?简单来说,跳表就是支持二分查找的有序链表
具体的搜索算法如下:
复制/* 如果存在 x, 返回 x 所在的节点, 否则返回 x 的后继节点 */private Node find(x){ p = top; while (true) { while (p.next.val < x){ p = p.next; } if (p.down == null){ return p.next; } p = p.down; } return null;}1.2.3.4.5.6.7.8.9.10.11.12.13.14. 插入关于插入,大家可能很容易想到往最下面一层的有序链表中添加数据,但是索引该咋办?索引要不要更新呢?
如果不更新索引,就可能出现两个索引节点之间数据非常多的情况,极端情况下跳表就会退化为单链表,从而使得查找效率从 O(LogN) 退化为 O(N)。
所以,我们在插入数据的时候,站群服务器索引节点也需要相应的改变来避免查找效率的退化
比较容易想到的做法就是完全重建索引,我们每次插入数据后,都把这个跳表的索引删掉全部重建。因为索引的空间复杂度是 O(N),即:索引节点的个数是 O(N) 级别,每次完全重新建一个 O(N) 级别的索引,时间复杂度也是 O(N) 。造成的后果是:为了维护索引,导致每次插入数据的时间复杂度变成了 O(N)。
那有没有其他效率比较高的方式来维护索引呢?
最理想的索引就是在原始链表中每隔一个元素抽取一个元素做为一级索引。换种说法,我们在原始链表中【随机】的选 n/2 个元素做为一级索引是不是也能通过索引提高查找的效率呢?
当然可以,云服务器因为一般随机选的元素相对来说都是比较均匀的。如下图所示,随机选择了 n/2 个元素做为一级索引,虽然不是每隔一个元素抽取一个,但是对于查找效率来讲,影响不大,比如我们想找元素 16,仍然可以通过一级索引,使得遍历路径较少了将近一半。

当然了,如果抽取的一级索引的元素恰好是前一半的元素 1、3、4、5、7、8,那么查找效率确实没有提升,但是这样的概率太小了。所以我们可以认为:当原始链表中元素数量足够大,且抽取足够随机的话,我们得到的索引是均匀的。所以,我们可以维护一个这样的索引:随机选 n/2 个元素做为一级索引、随机选 n/4 个元素做为二级索引、随机选 n/8 个元素做为三级索引,依次类推,一直到最顶层索引。这里每层索引的元素个数已经确定,且每层索引元素选取的足够随机,所以可以通过索引来提升跳表的查找效率。
那代码具体该如何实现,使得在每次新插入元素的时候,尽量让该元素有 1/2 的几率建立一级索引、1/4 的几率建立二级索引、1/8 的几率建立三级索引....呢?
其实很简单啦,搞一个概率算法就行了(具体是怎么个概率法这里就不详细解释了),当每次有数据要插入时,先通过概率算法告诉我们这个元素需要插入到几级索引中,然后开始维护索引并把数据插入到原始链表中。
如下所示,插入新元素 12,假设概率算法返回的结果是 4,表示新元素需要插入到 4 级索引中,同时,我们还需要建立 3 级索引、2 级索引和 1 级索引(也就是原始有序链表)
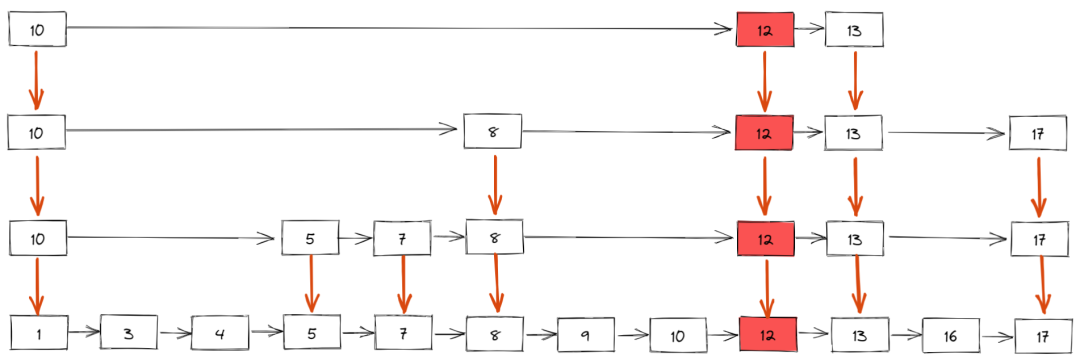
那插入数据时维护索引的时间复杂度是多少呢?
跳表中,每一层索引都是一个有序的单链表,元素插入到单链表的时间复杂度为 O(1),我们索引的高度最多为 LogN,当插入一个元素 x 时,最坏的情况就是元素 x 需要插入到每层索引中,所以插入数据的最坏时间复杂度是 O(LogN),最好的时间复杂度是 O(1)。
删除
跳表删除数据时,要把索引中对应节点也要删掉。如下图所示,如果要删除元素 8,需要把原始链表中的 8 和第 2、3 级索引的 8 都删除掉。
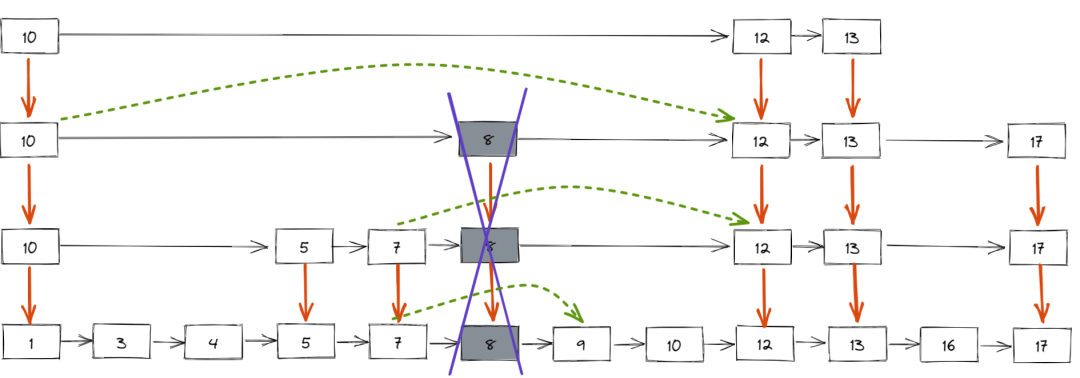
删除元素的过程跟查找元素的过程类似,只不过在查找的路径上如果发现了要删除的元素 x,则执行删除操作。
跳表中,每一层索引都是一个有序的单链表,单链表删除元素的时间复杂度为 O(1),最多需要删除 LogN 个元素(索引层数为 LogN),所以删除元素的总时间包 = 查找元素的时间 + 删除 LogN 个元素的时间 = O(LogN ) + O(LogN ) = 2O(LogN ),忽略常数部分,删除元素的时间复杂度为 O(LogN)。
你曾经考虑过 在 Ubuntu 中管理开机启动应用 吗?假如在开机时,你的 Ubuntu 系统启动得非常缓慢,那么你就需要考虑这个问题了。每当你开机进入一个操作系统,一系列的应用将会自动启动。这些应用被称为‘开机启动应用’ 或‘开机启动程序’。随着时间的推移,当你在系统中安装了足够多的应用时,你将发现有太多的‘开机启动应用’在开机时自动地启动了,它们吃掉了很多的系统资源,并将你的系统拖慢。这可能会让你感觉卡顿,我想这种情况并不是你想要的。让 Ubuntu 变得更快的方法之一是对这些开机启动应用进行控制。 Ubuntu 为你提供了一个 GUI 工具来让你找到这些开机启动应用,然后完全禁止或延迟它们的启动,这样就可以不让每个应用在开机时同时运行。在该文中,我们将看到 在 Ubuntu 中,如何控制开机启动应用,如何让一个应用在开机时启动以及如何发现隐藏的开机启动应用。这里提供的指导对所有的 Ubuntu 版本均适用,例如 Ubuntu 12.04, Ubuntu 14.04 和 Ubuntu 15.04。在 Ubuntu 中管理开机启动应用点击它来启动。下面是我的Startup Applications的样子:在 Ubuntu 中移除开机启动应用要将一个程序从开机启动程序列表中移除,选择对应的选项然后从窗口右边的面板中点击移除按钮来保留你的偏好设置。需要提醒的是,这并不会将该程序卸载掉,只是让该程序不再在每次开机时自动启动。你可以对所有你不喜欢的程序做类似的处理。让开机启动程序延迟启动这将展示出运行这个特定的程序所需的命令。保存并关闭设置。你将在下一次启动时看到效果。增添一个程序到开机启动应用列表中这将展示出在各种类别下你安装的所有程序。在 Ubuntu 的低版本中,你将看到一个相似的菜单,通过它来选择并运行应用。在各种类别下找到你找寻的应用,然后点击 属性 按钮来查看运行该应用所需的命令。例如,我想在开机时运行 Transmission Torrent 客户端。这就会向我给出运行 Transmission 应用的命令:接着,我将用相同的信息来将 Transmission 应用添加到开机启动列表中。第 2 步: 添加一个程序到开机启动列表中就这样,你将在下一次开机时看到这个程序会自动运行。这就是在 Ubuntu 中你能做的关于开机启动应用的所有事情。到现在为止,我们已经讨论在开机时可见到的应用,但仍有更多的服务,守护进程和程序并不在开机启动应用工具中可见。下一节中,我们将看到如何在 Ubuntu 中查看这些隐藏的开机启动程序。在 Ubuntu 中查看隐藏的开机启动程序复制代码代码如下:你可以像先前我们讨论的那样管理这些开机启动应用。我希望这篇教程可以帮助你在 Ubuntu 中控制开机启动程序。任何的问题或建议总是欢迎的。修改开机启动等待时间查看并修改配置文件 复制代码代码如下:复制代码代码如下:复制代码代码如下:我们可以将等待时间修改为自己想要的了。如:复制代码代码如下: